
Ethereum’s scaling journey has been defined by a single, stubborn bottleneck: the high cost and limited throughput of Layer 1 (L1) transactions. ZK-rollups have emerged as the most promising solution, radically reducing transaction fees and unlocking new levels of scalability. But how do they achieve such dramatic cost efficiency? The answer lies in three interlocking mechanisms: transaction batching, cryptographic data compression, and L1 data optimization via calldata minimization. Let’s break down how each works, why they matter, and what this means for users and developers seeking affordable, high-performance Ethereum experiences.
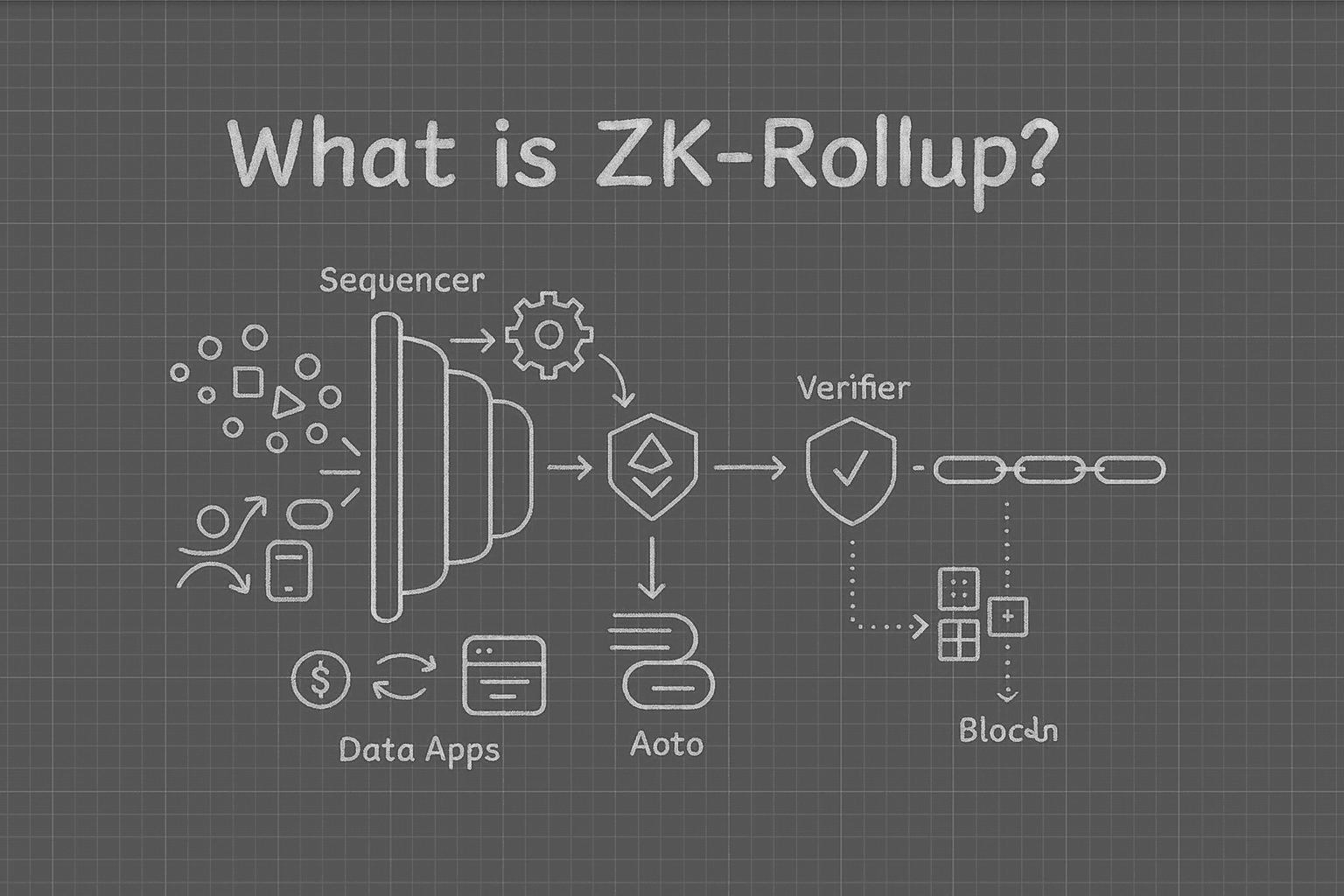
ZK-Rollup Transaction Batching: Amortizing Gas Costs at Scale
The first pillar of zk-rollup cost efficiency is transaction batching. Instead of processing each user transaction individually on Ethereum L1 (where every action incurs a hefty gas fee), zk-rollups aggregate hundreds or even thousands of transactions into a single batch. This batch is processed off-chain on the rollup’s Layer 2 (L2) environment. Once finalized, a succinct cryptographic proof attesting to the validity of all transactions in the batch is submitted to L1.
This approach fundamentally changes the fee structure. The fixed gas cost for posting to L1 is now shared by all transactions in the batch. For example, if a rollup batches 5,000 transfers and pays $10 in L1 gas fees, each user effectively pays just $0.002 per transaction - orders of magnitude cheaper than direct L1 activity. Recent market data shows that with optimized batching strategies, some zk-rollups have reduced amortized per-transaction gas costs to as low as 1,000, 2,000 gas units.
Cryptographic Data Compression: Minimizing What Must Be Posted On-Chain
The second lever for driving down costs is cryptographic data compression. Even after batching, posting every detail of every transaction would be prohibitively expensive. Zk-rollups sidestep this by using advanced cryptography - specifically succinct proofs like SNARKs or STARKs - to compress transaction data before it ever touches L1.
Instead of submitting full transaction histories or signatures on-chain, rollups post only the essential state differences ("state diffs") resulting from all included transactions. This drastically reduces both storage and bandwidth requirements on Ethereum mainnet. Studies indicate that as batch sizes grow, these compression techniques deliver even greater savings - making large-scale applications like DeFi trading or NFT minting economically viable for mainstream users.
L1 Data Optimization via Calldata Minimization: Only What Matters Gets Stored
The third mechanism - often overlooked but increasingly critical - is L1 data optimization via calldata minimization. Here’s where rollup architects get pragmatic: rather than posting redundant or reconstructible information to Ethereum (where every byte costs money), they submit only what’s strictly necessary for state verification and fraud prevention.
This usually means publishing compressed proof data alongside minimal state updates using efficient structures like sparse Merkle proofs. The introduction of Ethereum’s EIP-4844 upgrade further enhances this process by allowing state diffs to be sent as "blobs" instead of traditional calldata - slashing storage costs even more for rollups that adopt these features early.
By combining these three technical levers, zk-rollups have set a new standard for Ethereum scaling solutions. The impact is tangible: users enjoy dramatically lower transaction fees, while developers can build high-throughput applications without being hamstrung by L1 bottlenecks. These savings aren’t just theoretical - they’re being realized in production today, with leading rollups consistently delivering per-transaction costs that are a fraction of what’s possible on mainnet alone.
The Compound Effect: How the Three Mechanisms Reinforce Each Other
It’s important to recognize that transaction batching, cryptographic data compression, and L1 data optimization via calldata minimization don’t operate in isolation. Each amplifies the benefits of the others. Larger batches make compression more effective; better compression means less data for calldata minimization to optimize. This compounding effect is why zk-rollups are pulling ahead in the race for cost efficiency and throughput on Ethereum.
Comparison of Rollup Strategies: Transaction Costs and L1 Data Usage
| Rollup Strategy | Per-Transaction Gas Cost (Est.) | Data Posted to L1 | Data Optimization Technique |
|---|---|---|---|
| Classic ZK-Rollup (Batching Only) | ~2,000 gas | Full transaction data (calldata) | Batching transactions |
| ZK-Rollup with Compression | ~1,200 gas | Compressed state diffs | Batching + Cryptographic data compression |
| ZK-Rollup with L1 Data Optimization (EIP-4844) | ~1,000 gas | State diffs as blobs (minimal calldata) | Batching + Compression + Calldata minimization |
| Optimistic Rollup (for comparison) | ~3,000 gas | Full transaction data (calldata) | Batching transactions (no compression) |
For users, this translates to a seamless experience: faster confirmations, lower fees, and greater reliability even during periods of peak demand. For projects and protocols, it unlocks new business models and use cases - from microtransactions to real-time gaming - that were previously unfeasible due to prohibitive gas costs.
Challenges Ahead: Balancing Cost, Security, and Data Availability
No solution is without trade-offs. While zk-rollups drive down costs through aggressive batching and compression, there are ongoing debates about how much data must remain available on-chain to preserve trustlessness and censorship resistance. Innovations like Validium and Volition offer flexible tradeoffs between cost efficiency and data availability guarantees, allowing projects to fine-tune their approach based on risk tolerance and user needs.
The upcoming evolution of Ethereum’s protocol (including further EIP upgrades) will only expand the toolkit available for calldata minimization and state diff optimization - suggesting that we’re still early in the zk-rollup cost efficiency curve.
Why This Matters Now: The Future of Affordable Ethereum
The market context couldn’t be clearer: as activity on Ethereum surges into 2025, demand for scalable solutions with sustainable fee models is at an all-time high. Zk-rollups’ multi-pronged approach - leveraging transaction batching, cryptographic data compression, and calldata minimization - isn’t just a technical curiosity; it’s a blueprint for mainstream blockchain adoption.
If you’re building or investing in Ethereum-based applications today, understanding these mechanisms isn’t optional - it’s essential for staying competitive as network dynamics evolve.




No comments yet. Be the first to share your thoughts!